La diffusion de nos résultats scientifiques est au cœur de notre mission : elle permet de partager et de rendre accessibles les avancées en recherche à un public élargi. Au-delà des publications dans des revues spécialisées, l’IMBE déploie de nombreux moyens pour vulgariser les connaissances et les rendre compréhensibles et attractives à des audiences diversifiées. Par des actions concrètes et des outils innovants, nous nous engageons à rapprocher la science de tous, afin d’établir un dialogue permanent entre les sciences, la recherche et l’ensemble de la population, notamment les plus jeunes.
Recherches
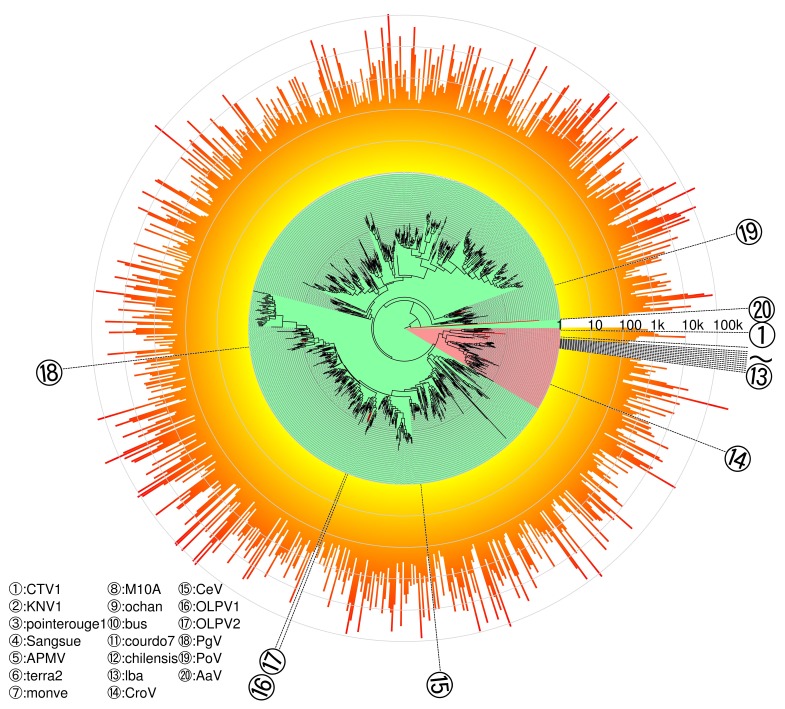
En tant que participant à l’expédition pan-océanique Tara Oceans, j’ai oeuvré pour mettre les données de génomique produites à disposition de la communauté scientifique.
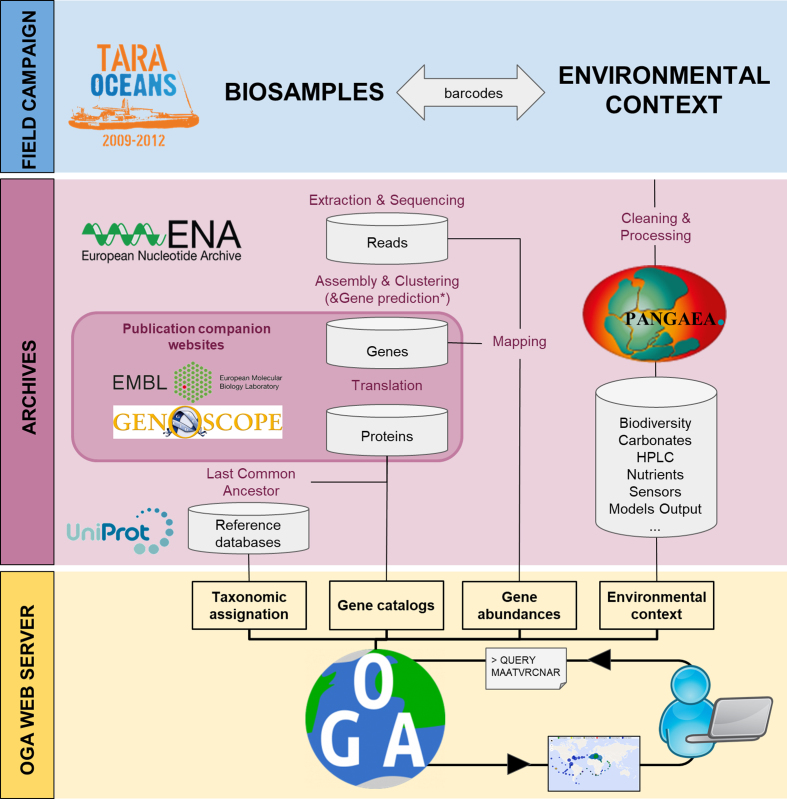
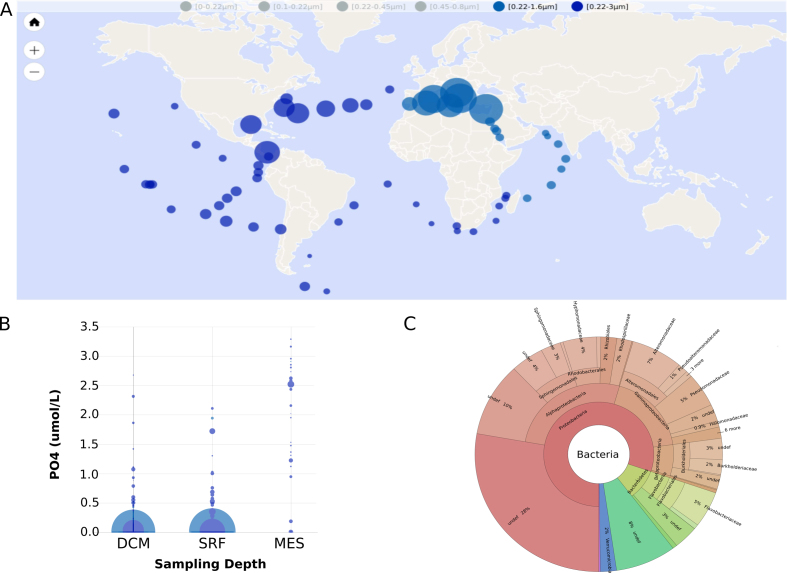
Etant donné le volume des jeux de données de génomique issu du projet (Tara Ocean c’est plus de 600 terabases évolutives), la transformation de ces données brutes en connaissances s’avère difficile pour les biologistes sans savoir-faire et matériel de calcul haute performance. Avec mes collègues de l’Institut Méditerranéen d’Océanologie, nous avons donc développé le Ocean Gene Atlas (OGA), un outil d’exploration des métagénomes en ligne qui permet la fouille de données armé d’un seul navigateur web. De plus, la manipulation de cet ensemble de données hétérogènes (qui combine des séquences biologiques, des estimations d’abondances à partir des reads bruts, et des métadonnées environnementales) étant également complexe pour des experts en bioinformatique, nous avons donc également mis en place une API pour un accès programmatique complet aux données et outils d’analyse OGA. Plus de détails sur les données, les méthodes et les visualisations sont à lire dans le papier NAR « The Ocean Gene Atlas: exploring the biogeography of plankton genes online ».
L’Ocean Gene Atlas est l’aboutissement d’un projet de près d’une décennie qui a démarré avec une campagne d’échantillonnage en mer, suivi d’une demi-douzaine d’années supplémentaires d’acquisition de données (extraction d’ADN/ARN, séquençage), d’analyses primaires des données brutes (assemblage, annotation), puis enfin l’intégration dans des produits finaux exploitables (analyses, publication, jeux de données, outils). J’ai eu le privilège de prendre part à toutes les étapes, y compris deux embarquements en tant que membre d’équipage scientifique (mer Méditerranée, Atlantique sud) en charge des échantillonages de bactéries et virus, et un embarquement en tant que chef de mission (Océan Arctique le long des côtes Sibériennes). Comme quoi bioinformaticien ce n’est pas rester greffé à son écran…
Enseignements
Avec 25 années de recul sur l’enseignement de la bioinformatique à l’université, j’ai migré la majeure partie de mes cours dans un format « les mains dans le cambouis », centré sur l’analyse de données réelles issues de la recherche.
En soutien à une telle approche qui pose des défis dans le cas de larges cohortes d’étudiants, j’ai développé l’Annotathon, un environnement Internet pour l’apprentissage des méthodes bioinformatiques d’analyse de séquence. Dans cette stratégie de classe inversée, les participants ajoutent à leur panier de séquences des fragments d’ADN génomique environnementaux (par exemple issus de différents océans du projet Tara Océans ou de sites du corps humain du Human Microbiome Project, voire en 2021 des génomes de coronavirus) puis les annotent. Les analyses comprennent la détection de régions codantes, la recherche de séquences homologues dans les banques de séquences, l’identification de domaines protéiques conservés ainsi que la construction d’arbres phylogénétiques.
Conçu pour gérer de larges cohortes de participants (dénommées équipes, par exemple des promotions d’étudiants), les investigations sont encadrées par des enseignants. Chaque séquence annotée par chaque participant est examinée, commentée et évaluée par les enseignants à deux reprises, permettant aux participants de se corriger et d’améliorer la qualité de leurs analyses. Après la clôture d’une session, les participants peuvent recevoir une évaluation quantitative pour l’ensemble de leurs annotations.
Plus de 200 cohortes d’apprenants ont été formées via L’Annotathon depuis sa première livraison en 2005, avec des équipes qui nous ont rejoint de tous les continents après que l’Annotathon ait été décrit dans le numéro de novembre 2008 de PLoS Biology “Metagenome Annotation Using a Distributed Grid of Undergraduate Students” . J’ai également eu le plaisir d’enseigner la bioinformatique en présentiel en s’appuyant sur l’infrastructure Annotathon à Brazzaville (Congo en 2009, 2011, 2012, 2013 & 2014), Hanoi (Vietnam en 2015 & 2018) et au Koweit (2009).